
A new architecture for ocean observations
First principles + new scaling roadmaps
Oceans are vast, crucial parts of the environment and our economy, but understanding how they work— measuring them at scale —is expensive. This is why Walter Munk, one of the first physical oceanographers to apply statistical methods to analyzing oceanographic data, dubbed the 1900s “the century of undersampling.”
Most of the previous century could be called a century of undersampling.
We’re limited in the amount of granular data we can collect. This limits the effectiveness of our shipping and logistics, aquaculture, and climate modeling. It limits our ability to predict the weather, including catastrophic events such as hurricanes. And it limits our ability to rapidly construct offshore wind farms while protecting endangered North Atlantic Right whales. High information costs hinder informed decisions.
We need more persistent and pervasive ocean measurements, gathered for longer durations and over larger areas, to obtain transformative insights that are imperative across large markets. But it can’t just be about quantity, or even quality of the data collected; the cost has to be reasonable. How do we cover new areas of the map affordably? How can we build on the success of a few large-scale ocean observing networks that— while innovative —have only skimmed a portion of the ocean?
Our vision at Apeiron Labs is to provide upper ocean data, anywhere on the planet, delivered on-demand. To do this, we need to rethink the fundamental architecture of ocean observation and our metrics for upper-ocean monitoring— delivering data that is consistent, impactful, and at a fraction of the cost per data point than is feasible today.
Standing on the shoulders of giants
We’re standing on the shoulders of giants here— specifically Argo, the network of autonomous floats deployed throughout the world’s oceans, which gather data that help us understand the complex dynamics of oceanic ecosystems and climate patterns.
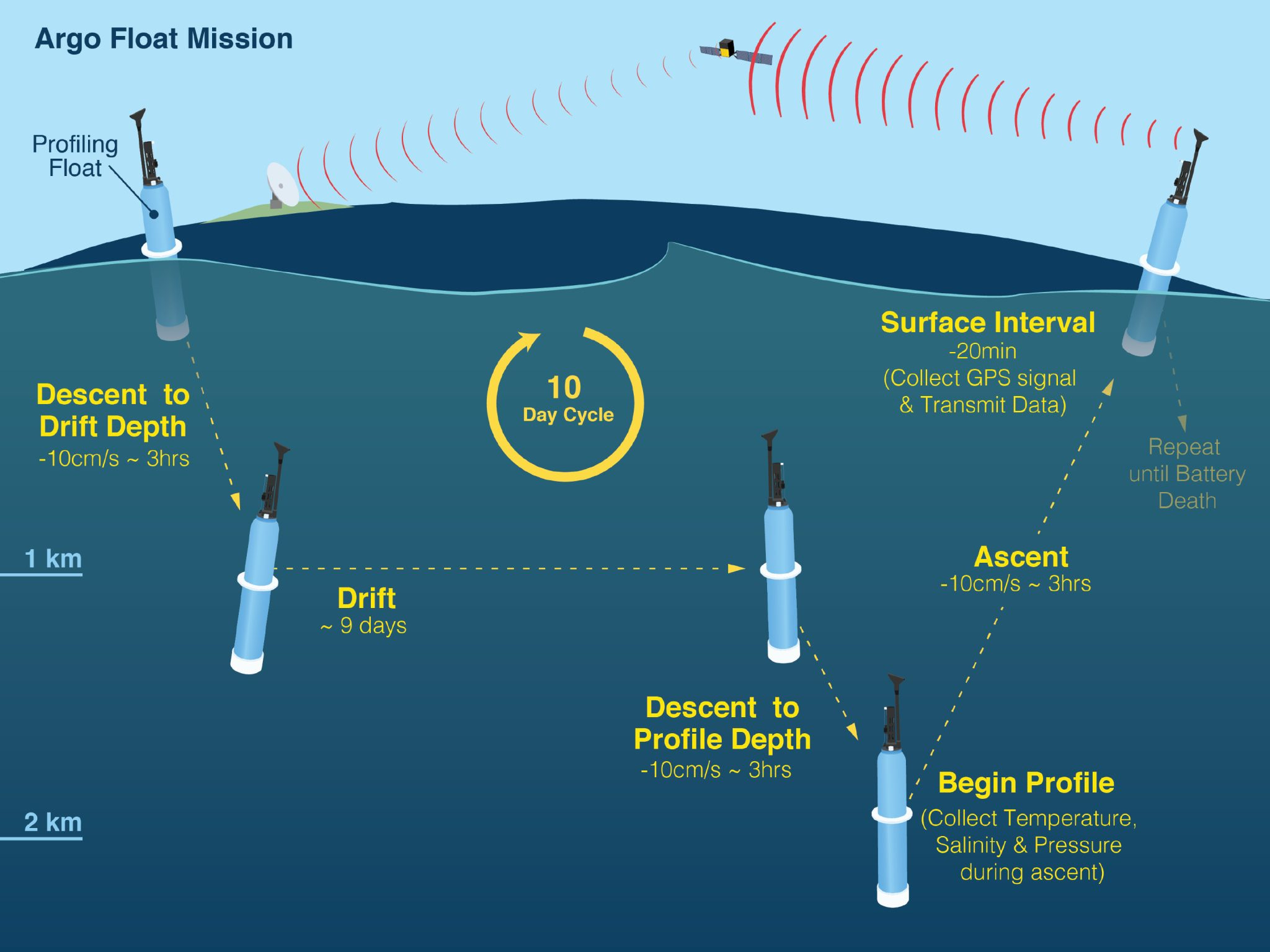
Over 4,000 floats in the Argo network wend their way through the ocean, periodically descending down to 2,000 meters, or a little over a mile, deep into the water; as they ascend, the floats’ sensors collect data on temperature, salinity, and pressure; the data is then transmitted via satellites once the floats resurface to be processed and stored in database that can be accessed by anyone for free. This technology offers a huge cost improvement compared to traditional methods, which Munk aptly described as “the expedition mode of oceanography…of a few ships chasing the vast oceans…and successive measurements differed in space and time.” And it provides unparalleled insight into understanding the ocean.
Argo has gone well beyond the “the expedition mode of oceanography, of a few ships chasing the vast oceans”
Let’s try to look at what it costs to get a single temperature reading from a single Argo float over the course of a single mission. This is the metric we are really after - not how far the floats travel, or how deep, or long they can endure. We want to know — like a car’s fuel efficiency in miles per gallon or a solar panel’s cost per watt — how much data we are getting per dollar spent, and how to develop a roadmap to lower this over time. The ocean is such an enormous reservoir of heat and carbon dioxide, responsible for regulating the Earth’s temperatures, that we need to (ideally) measure its temperature on a near real-time basis to correctly plan and forecast. So, how much do we pay for a single temperature measurement towards that goal?
Fortunately for us, it’s fairly simple to determine this. Each temperature-salinity profile collected by Argo costs ~$200 and reports around 80 data points on average, yielding a cost of $2.50 per data point. This is likely a lower bound on the cost, with $1.25 attributable to hardware and $1.25 to operations. In this architecture, even if the hardware had zero cost, we could only lower the cost per data point by a factor of 2. Now imagine what it would take to lower this cost by 10X or 100X. What would it take to bring some well-known scaling laws (e.g., Wright’s Law) to ocean data? How can we do for ocean data what SpaceX and RocketLab did for rocket launch costs over the past fifteen years?
A new way forward
We firmly believe that the way forward requires a completely novel architecture for scalable ocean observations. We are building a roadmap that includes going back to first principles, innovations in autonomous underwater vehicle technology as well in the operating system that orchestrates millions of AUVs at planetary scale. We will leverage existing scaling curves — from manufacturing, communication, computing — and build some scaling curves of our own. One thing is clear: We need to keep our focus on technology-agnostic metrics — the cost per data point or the cost per whale detected, for example. That will steer us in the right direction.

With this focus, it’s our hope that this first century of the new millennium can be dubbed, by future observers and historians, as “the century of right-sized sampling” Or maybe it’ll be “the century of ample sampling” (Both sound mighty!) However they phrase it, this will be the era in which the vast and complex ocean becomes much better understood thanks to an influx of new data. Upper ocean data, anywhere on the planet, delivered on-demand.
Work is already well underway—and you’ll hear about it here first.
Visit apeironlabs.com to learn more.